Version imprimable du sujet
Cliquez ici pour voir ce sujet dans son format original
Forums MacBidouille _ Technologies Apple _ Effacer des caractères compris entre deux zones
Écrit par : EmatuM 12 Jan 2021, 01:15
Bonjour 
Je suis en train de créer un script afin d'épurer un fichier CSV que je récupère de ma banque en ligne afin d'inclure son contenu dans un tableau Excle.
Le problème c'est que j'ai certaines transactions qui contiennent d'innombrables caractères qui ne servent à rien.
Pour imager cela, voilà un exemple (j'ai volontairement modifier certaines données mais la structure est la même) :
PRLV SEPA XXX : IT00000000000 00000000000000000000000000000000000 DE XXX : 00000000000000000000000000000000000 IT00000000000;;50,00;EUR;
Ce que je souhaiterais faire, c'est de supprimer l'ensemble des caractères qui sont en gras.
Je n'arrive pas à trouver la bonne commande qui permette de faire cela.
Si une âme charitable pouvait m'aiguiller. Merci 
Écrit par : baron 12 Jan 2021, 01:37
Le problème est toujours de déterminer quel est le pattern pertinent.
Ensuite, il ne doit pas être très difficile de créer une expression régulière qui le décrive (avec une recherche https://fr.wikipedia.org/wiki/Grep.)
Est-ce que toutes les parties que tu veux effacer, et seulement elles ! pourraient être décrites comme suit :
« Une chaîne de caractères quelconques, qui commence avec le premier deux-points rencontré dans un paragraphe et qui se termine devant le premier point-virgule ? »
Avec un seul exemple, c'est impossible à déterminer… mais sinon, inspire-toi de cet exemple pour décrire ce qui doit être recherché.
Écrit par : jeandemi 12 Jan 2021, 09:49
Ce sont toujours les mêmes caractères (comme lorsque les caractères accentués sont remplacés) ou ils changent ?
Dans le premier cas, tu peux utiliser la fonction rechercher/remplacer
Écrit par : EmatuM 12 Jan 2021, 12:33
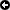
En effet on peut par exemple voir pour un pattern qui dirait "commence par les 2 points et supprime tous les caractères (quelconques) jusqu'au point virgule"
L'idée étant de supprimer également les 2 points du début, mais de ne pas supprimer le point virgule.
Dans le premier cas, tu peux utiliser la fonction rechercher/remplacer
Alors c'est possible en effet car il me semble que les caractères sont toujours les mêmes. J'ai déjà exploité cette méthode avec le pattern suivant pour d'autres éléments qui se trouvaient à plusieurs endroits.
set text of front document to replace_eur(text of front document, "eur", "") of me
on replace_eur(le_texte, recherche, replace)
set AppleScript's text item delimiters to the recherche
set the item_list to every text item of le_texte
set AppleScript's text item delimiters to the replace
set le_texte to the item_list as string
set AppleScript's text item delimiters to ""
return le_texte
end replace_eur
Le problème c'est que là, ça fait un sacré paquet pour une seule chose à supprimer. Cette fonction ci-dessus est utile quand tu as plusieurs lignes dans un même fichier. Je ne trouve pas cela pertinent d'écrire un si gros paquet pour seulement une ligne de caractère qui n'apparait qu'une fois par mois dans mes relevés de compte.
Écrit par : EmatuM 16 Jan 2021, 12:55
Un UP pour savoir si quelqu'un n'a pas une solution à me proposer SVP ?
Merci
Écrit par : PBell 16 Jan 2021, 13:19
Bonjour,
Petite suggestion:
si tu t'intéresses à ce qui est après les ; pourquoi ne pas utiliser ce ; comme AppleScript's text item delimiters
Dans ton exemple, les '50.00' sont dans le text item 3 et 'Euro' dans ton texte item 4.
N'est-ce aps ce que tu recherches ?
Cordialement
Écrit par : EmatuM 21 Jan 2021, 13:05
Petite suggestion:
si tu t'intéresses à ce qui est après les ; pourquoi ne pas utiliser ce ; comme AppleScript's text item delimiters
Dans ton exemple, les '50.00' sont dans le text item 3 et 'Euro' dans ton texte item 4.
N'est-ce aps ce que tu recherches ?
Cordialement
Je n'ai pas bien saisi ce que tu me proposes. En gros tu me demandes de réutiliser la fonction que j'ai mise en exemple c'est ça ?
Écrit par : PBell 21 Jan 2021, 21:14
Bonsoir,
L'idée est bien d'utiliser les item text delimiteurs, mais de façon plus simple:
Voici un example avec une ligne:
set AppleScript's text item delimiters to {";"}
set Montant to text item 3 of ligne
La variable Montant contient directement "50,00". De la même façon, the text item 4 of ligne contiendra "EUR".
N'est-ce pas ce que tu souhaites de nettoyer tout ce qui est devant le montant ?
Cordialement
Écrit par : EmatuM 24 Jan 2021, 17:40
L'idée est bien d'utiliser les item text delimiteurs, mais de façon plus simple:
Voici un example avec une ligne:
set AppleScript's text item delimiters to {";"}
set Montant to text item 3 of ligne
La variable Montant contient directement "50,00". De la même façon, the text item 4 of ligne contiendra "EUR".
N'est-ce pas ce que tu souhaites de nettoyer tout ce qui est devant le montant ?
Cordialement
Merci pour ta réponse. En fait pas devant le montant mais entre le XXX et le premier point virgule.
En gros, je te mets en gras souligné ce que je voudrais voir disparaitre
PRLV SEPA XXX : IT00000000000 00000000000000000000000000000000000 DE XXX : 00000000000000000000000000000000000 IT00000000000;;50,00;EUR
J'aimerais simplement pouvoir arriver à la structure suivante écrite exactement ainsi :
PRLV SEPA XXX ;50,00;EUR
Par contre tu parles de TEXT ITEM 4 OF LINE alors que dans ton code il est écrit TEXT ITEM 3 OF LINE. Est-ce une coquille ou n'ai-je pas compris pourquoi dans un cas tu écris 3 et après tu parles de 4 ?
Écrit par : Zeltron54 24 Jan 2021, 21:55
Le script que tu cherches à faire est:
A la fin la variable laligne contient ce que tu cherches. J'ai ajouté un "display dialog" qui te permet de l'afficher
set sauv to AppleScript's text item delimiters
set AppleScript's text item delimiters to {";"}
set part1 to text item 1 of ligne
set part2 to (text item 3 of ligne) & ";" & (text item 4 of ligne)
set AppleScript's text item delimiters to {":"}
set part1 to text item 1 of part1
set laligne to part1 & ";" & part2
set AppleScript's text item delimiters to sauv
display dialog laligne
Écrit par : PBell 25 Jan 2021, 17:29
Bonjour,
Désolé, je n'ai pas vu ta réponse hier soir. Compte tenu de ce que tu souhaites, il suffit de combiner les delimiter en une seule liste de 2 delimiters: le : et le ;
Voici le script le plus simple:
set AppleScript's text item delimiters to {";", ":"}
set R to (text item 1 of ligne) & ";" & (text item 5 of ligne) & ";" & (text item 6 of ligne)
log R
Le script lui-même tient en 2 lignes sur les 4.
La ligne 1 est pour assigner une valeur d'exemple à la variable Ligne. La ligne 4 est pour voir le résultat qui est conforme à ton souhait:PRLV SEPA XXX ;50,00;EUR
Cordialement
Écrit par : g4hd 25 Jan 2021, 18:27
Est-ce qu'il s'agit d'intervenir sur une petite quantité de fichiers (une dizaine ?) ou bien plusieurs dizaines ?
Je demande cela parce qu'il y a moyen de faire cela en "visuel" à la souris, à l'aide de fonctionnalités simples comme Renommer/Remplacer sur un nombre réduit de fichiers listés.
Je pratique cela (10 minutes tous les 3 mois) pour mes relevés bancaires Banque Populaire qui sont maintenant dénommés avec dates "jjmmaaaa" après l'intervention d'un crétin qui a décidé que c'est mieux que le précédent classement par dates "aaaammjj"… qui classe automatiquement dans l'ordre chronologique.
(Faut-il expliquer la non-réaction arrogante de cette banque quand on essaye de leur faire comprendre ?)
Exemples de classement idiot jjmmaaaa (sur les 4 premiers mois de l'année) :
Relevé du 15012020
Relevé du 15022020
Relevé du 15032020
Relevé du 15042020
Relevé du 29022020
Relevé du 30042020
Relevé du 31012020
Relevé du 31032020
Les mêmes remis en classement chronologique aaaammjj :
Relevé du 20200115
Relevé du 20200131
Relevé du 20200215
Relevé du 20200229
Relevé du 20200315
Relevé du 20200330
Relevé du 20200415
Relevé du 20200430
Écrit par : EmatuM 27 Jan 2021, 17:46
PBell et Zeltron54
Merci pour vos réponses, je vais regarder cela.
g4hd
En fait je le faisais déjà à la main à l'époque sans même passer par la fonction Recherche/Remplace vu que ça ne concerne qu'une seule ligne sur chaque relevé de compte.
Le truc c'est qu'étant donné que j'avais créé le reste du script pour remplacer plusieurs autres éléments (là pour le coup plusieurs fois la même chose dans chaque relevé) tant qu'à faire je voulais que cette étape se fasse aussi via le script. Autant tout faire en une fois au lieu de faire la moitié avec le script, l'autre moitié à la main. Ca n'aurait du coup aucun intérêt de faire un script qui ne te mâche que la moitié du boulot, n'est-ce pas ? 
Propulsé par Invision Power Board (http://www.invisionboard.com)
© Invision Power Services (http://www.invisionpower.com)