

 |
Bienvenue invité ( Connexion | Inscription )
  |
 14 Nov 2014, 11:37 14 Nov 2014, 11:37
Message
#41
|
|
 Macbidouilleur de vermeil !  Groupe : Membres Messages : 1 076 Inscrit : 16 Dec 2002 Membre no 5 167 |
Citation (JoKerforever @ 13 Nov 2014, 10:01)  Citation (Mac Moins @ 13 Nov 2014, 09:42) Je pense à un truc du genre MacTracker qui donne plein d'informations mais pas de mesure comparative de puissance. MacTracker à pourtant une rubrique Benchmarks dans la partie processeur pour quasiment tout les modèles. Ah oui, j'avions point vu. Merci. En admettant que c'est représentatif, mon imac fait quatre fois moins bien qu'un imac actuel. Ils auraient gardé des écrans mats que ça me donnerait envie de moderniser mon engin... -------------------- Co-fondateur et Administrateur de l'U.P.L.
Membre du club des AIPBP (Anciens Inscrits Pas Beaucoup de Posts) Voir la liste |
 |
 
|


|
14 Nov 2014, 16:50
Message
#42
|
|
 Macbidouilleur d'Or ! Groupe : Membres Messages : 3 458 Inscrit : 23 Mar 2004 Lieu : Paris / Vancouver Membre no 16 640 |
Citation (SartMatt @ 13 Nov 2014, 20:26) Citation (r@net54 @ 13 Nov 2014, 19:02) Il faut rajouter que la grosse evolution en terme de processeur c'est la reduction de consommation, parce que la puissance brute elle stagne méchamment depuis 2007 sur x86: Bien essayé... Mais : 1) SuperPi est un benchmark qui n'utilise aucune nouvelle instruction. C'est bien pour comparer les performances brutes sur quelques opérations simples, mais ce n'est absolument pas représentatif de l'évolution des performances réelles à l'usage sur pas mal de tâches, car toutes les applications d'aujourd'hui utilisent les nouveaux jeux d'instructions... C'est particulièrement vrai par exemple pour tout ce qui est applications multimédia, où l'apport des nouvelles instructions peut parfois se traduire par un doublement des performances d'une génération à l'autre, même si les performances en arithmétique pure n'ont presque pas bougé. 2) L'auteur de ce graphique a choisi une échelle linéaire pour le temps de calcul : c'est complètement con comme échelle ! Une échelle linéaire sur un temps de calcul, ça fait qu'une augmentation exponentielle des performances donne une courbe logarithmique : c'est totalement biaisé, ça donne l'impression que la progression est de plus en plus faible. À plus forte raison, quand le progression n'est plus exponentielle, une représentation logarithmique "écrase" encore plus la courbe, renforçant l'impression de stagnation. En l'occurrence, la "méchante stagnation" depuis 2007, c'est quand même une multiplication des performances par un facteur supérieur à 2 (certes, on était auparavant plus habitué à voir ça sur deux ans, voir moins), sur du code ne profitant pas des plus grosses améliorations... SuperPi évalue la puissance de calcul brute du core comme tu le reconnais. Il n'évalue pas les autres unites comme les unites de traitement vectoriel, les unite de gestion I/O, les equivalents des DSP, etc. Ce test est donc représentatif de la puissance de calcul en monocore. il est valable et représentatif de la progression reelle de la puissance. Et cette puissance de calcul est celle du CPU. Si on veut évaluer la puissance en vectoriel, par exemple pour le traitement video, les CPU sont totalement écrasés par le GPGPU. Pareil pour le traitement de signal. Je sais que ca fait mal de voir ca, mais le choix de la representation est legitime et significative. Le systeme est simple et il dit bien ce qu'il veut dire: combien de temps met un processeur pour realiser un calcul standard? Il dit donc que depuis 2007 il n'y a pas eu d'evolution significative sur la puissance de traitement: le temps necessaire pour realiser le calcul étant quasi le meme depuis 7 ans, ce que tu reconnais aussi! Quant a la complexité de l'architecture, tu détournes volontairement le sujet sur le nombre de composants (transistors). Ca n'a rien a voir évidemment avec la complexité de l'architecture. Dans un x86 on a au moins 1 niveau de pre-traitement et de post-traitement des données supplémentaires, donc ca augmente la complexité d'au moins 2 niveaux. D'ailleurs tu le sais pertinemment. Intel a un savoir faire en terme d'optimisation de rendement qui est superieur a la majorite des autres concepteurs de CPU, a part IBM. Ils disposent aussi d'un savoir faire en terme de gravure parmi les meilleurs. Pourquoi avec une telle avance ils n'arrivent pas avec les Atom a écraser les ARM? Si aujourd'hui TSMC est en train de faire son retard sur Intel en terme d'efficacite de gravure, c'est tout nouveau et ils sont pas encore aussi efficace qu'Intel. Donc on a un x86 totalement maitrisé optimisé comme une formule 1 par des ingenieurs qui sont les meilleurs au monde et en face on a de l'ARM qui est encore tres loin d'etre aussi optimisé et qui est moins maitrisée. Donc la marge de progression entre le x86 et l'ARM n'est pas la meme. La difference c'est l'efficacité de l'architecture:CQFD. Ce message a été modifié par r@net54 - 14 Nov 2014, 17:03. -------------------- Agnostique multipratiquant: Unixs, Linux, Mac OS X, iOS et un peu de Windows. Des Macs, des iDevices, des PC et des "ordinosaures"…
Citation « Celui qui t’entretient des défauts d’autrui entretient les autres des tiens. », Diderot« Quand on suit une mauvaise route, plus on marche vite, plus on s'égare. » |
|
|
|

|
14 Nov 2014, 17:16
Message
#43
|
|
 Macbidouilleur d'Or ! Groupe : Membres Messages : 3 515 Inscrit : 21 Sep 2005 Membre no 46 410 |
Citation (r@net54 @ 14 Nov 2014, 16:50) SuperPi évalue la puissance de calcul brute du core comme tu le reconnais. Il n'évalue pas les autres unites comme les unites de traitement vectoriel, les unite de gestion I/O, les equivalents des DSP, etc. Ce test est donc représentatif de la puissance de calcul en monocore. il est valable et représentatif de la progression reelle de la puissance. Et cette puissance de calcul est celle du CPU. Si on veut évaluer la puissance en vectoriel, par exemple pour le traitement video, les CPU sont totalement écrasés par le GPGPU. Pareil pour le traitement de signal. Je sais que ca fait mal de voir ca, mais le choix de la representation est legitime et significative. Le systeme est simple et il dit bien ce qu'il veut dire: combien de temps met un processeur pour realiser un calcul standard? Il dit donc que depuis 2007 il n'y a pas eu d'evolution significative sur la puissance de traitement: le temps necessaire pour realiser le calcul étant quasi le meme depuis 7 ans, ce que tu reconnais aussi! Ça revient à mesurer la vitesse maximale d'une voiture en la bloquant au 1er rapport de sa boîte de vitesse. Ce n'est donc absolument pas significatif pour la vie de tous les jours. |
|
|
|
|
14 Nov 2014, 17:47
Message
#44
|
|
|
Macbidouilleur d'Or ! Groupe : Rédacteurs Messages : 32 233 Inscrit : 15 Nov 2005 Membre no 49 996 |
Citation (r@net54 @ 14 Nov 2014, 16:50) Ce test est donc représentatif de la puissance de calcul en monocore. Dans un contexte bien particulier. Donc pas représentatif de la réalité.Citation (r@net54 @ 14 Nov 2014, 16:50) Si on veut évaluer la puissance en vectoriel, par exemple pour le traitement video, les CPU sont totalement écrasés par le GPGPU. Sauf qu'il y a dans la réalité énormément de logiciels qui font appel à ces unités vectorielles (y compris les OS eux mêmes), sans pour autant faire appel au GPGPU. Donc ignorer totalement ces unités dans les tests, ce n'est pas du tout représentatif de l'usage réel.Et les nouvelles instructions qui sont apportées à chaque génération de CPU, c'est pas forcément que sur du vectoriel, c'est parfois aussi sur de l'arithmétique de base, sur de la manipulation de chaînes de caractères, etc... Citation (r@net54 @ 14 Nov 2014, 16:50) Je sais que ca fait mal de voir ca, mais le choix de la representation est legitime et significative. Désolé, mais non. Un choix de présentation graphique qui transformerait une croissance exponentielle en courbe logarithmique, ce n'est pas très légitime, c'est une façon de biaiser la perception qu'on fait du résultat...Il dit donc que depuis 2007 il n'y a pas eu d'evolution significative sur la puissance de traitement: le temps necessaire pour realiser le calcul étant quasi le meme depuis 7 ans, ce que tu reconnais aussi! Depuis 7 ans, si on regarde la courbe on a l'impression que ça n'a pas bougé d'un poil. Si on fait un peu plus attention, on voit qu'il y a une progression d'un facteur de l'ordre de deux, ce qui reste loin d'être négligeable (surtout que dans le même temps, on a aussi quadruplé le nombre de cœurs...). Refait la courbe en prenant la vitesse de traitement au lieu du temps de traitement, elle donnera une vision nettement différente. EDIT : tiens en prime pour ajouter au caractère non représentatif de ce graphique, il ne s'agit pas de l'évolution des performances des CPU commerciaux, mais de l'évolution des records de performances avec des CPU overclockés à mort (c'est dommage de devoir aller chercher moi même ce genre d'infos... si t'avais un minimum d'honnêteté intellectuelle, tu aurais précisé dès le départ le nom du bench, le type de processeurs testés, etc... mais non, toi tu balances juste une courbe sans légende...)... Or, les CPU d'il y a quelques années avaient souvent une marge de progression en OC bien plus importante : les Pentium 4 étaient essentiellement limités par leur dissipation thermique, donc s'envolaient dès qu'on les mettait sous azote, ce qui est beaucoup moins vrai avec les CPU d'aujourd'hui. Tiens, cadeau, voilà la courbe de la vitesse de traitement (tiens, je fait comme toi, je met pas de légende... mais au moins on sait de quoi je parle) : 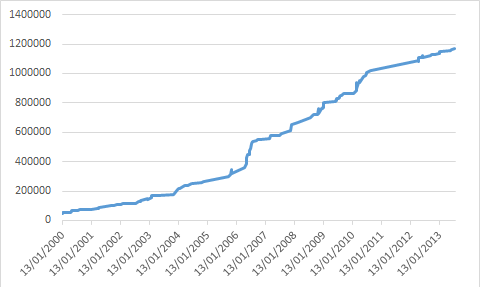 Qu'est ce qu'on voit alors ? Les performances ne stagnent pas depuis 2007, elles ont simplement cessé d'avoir une progression exponentielle pour s'approcher de quelque chose de plutôt linéaire. Mais le plus intéressant à mon sens, c'est cette courbe là, qui correspond au rapport de performances sur 3 ans : 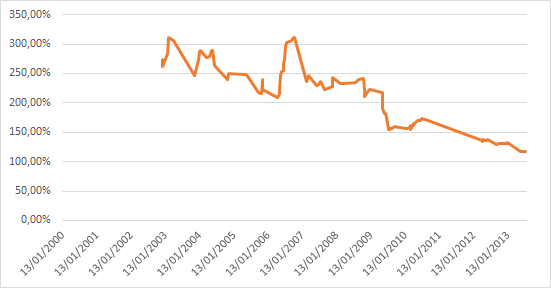 On voit bien qu'il y a une diminution de la progression de performances, mais on voit aussi qu'on n'est pas encore en stagnation sur 3 ans, et à fortiori encore moins sur 7 ans (la stagnation correspond à 100%). Et c'est sans compter l'impact de la multiplication des cœurs et sans regarder le rapport performances/consommation... Mais ça serait par contre bien plus intéressant de faire ça avec des chiffres de performances à la date de sortie pour des processeurs à leur fréquence normale. Des chiffres réalistes quoi... Citation (r@net54 @ 14 Nov 2014, 16:50) Quant a la complexité de l'architecture, tu détournes volontairement le sujet sur le nombre de composants (transistors). Ca n'a rien a voir évidemment avec la complexité de l'architecture. Dans un x86 on a au moins 1 niveau de pre-traitement et de post-traitement des données supplémentaires, donc ca augmente la complexité d'au moins 2 niveaux. Euh si, complexité et nombre de transistors sont quand même assez liés... Et au contraire, tu peux avoir un processeur plus simple tout en ayant plus de niveaux, les différents niveaux pouvant être plus ou moins complexes...Mais bon, puisque tu es convaincu que seul ne nombre de niveaux compte, regardons le le nombre de niveaux... Tu dis qu'il y a au moins deux niveaux de plus ? Ben non Le pipeline du Haswell fait entre 14 et 19 niveaux selon les cas, Bay Trail 14 à 17. Un Cortex A15, c'est 15 niveaux pour les entiers, 17 à 25 niveaux pour les flottants. Et pour l'A8, c'est en moyenne au moins 16 niveaux, et généralement compris entre 14 et 19 niveaux (oui, pile poil comme Haswell) (cf AnandTech : http://www.anandtech.com/show/7910/apples-...ecture-detailed , la longueur du pipeline étant forcément supérieure ou égale à la pénalité en cas de mauvaise prédiction de branchement). Accessoirement, comme tu l'auras déduit de ces chiffres, le nombre de niveaux à traverser pour traiter une instruction ne dépend pas de l'architecture, mais de la microarchitecture. D'un processeur ARM à l'autre, on n'a pas le même nombre de niveaux, tout comme il varie d'un processeur x86 à l'autre. Mais on constate que tous les CPU ARM hautes performances ont des pipelines du même ordre de longueur que ceux des Intel haut de gamme. Citation (r@net54 @ 14 Nov 2014, 16:50) Pourquoi avec une telle avance ils n'arrivent pas avec les Atom a écraser les ARM? Mais quelle avance ? C'est tout le contraire, le x86 est arrivé très tard sur le marché de l'ultramobilité, alors qu'ARM y était déjà en quasi monopole. ARM est présent sur les PDA/smartphones depuis 15/20 ans, le x86 depuis 4-5 ans (Atom Z500, lancé en juin 2010). Et en prime, Intel est arrivé avec un SoC incomplet par rapport à ceux du leader (Qualcomm), donc handicapant (pas de baseband intégré au SoC).Et quand tu arrives ainsi bien après le concurrent, c'est jamais facile de rattraper le retard, surtout avec des OS et des logiciels optimisés uniquement pour le concurrent, et les pertes liées à l'émulation/traduction pour tous les logiciels qui n'auront pas été portés en natif. On voit d'ailleurs bien que le seul marché de l'ultra-mobilité sur lequel ARM n'est pas arrivé bien avant le x86, il est déjà quasiment perdu pour ARM : il ne sort quasiment plus aucune nouvelle tablette Windows ARM, toute la production a basculé sur le x86. Citation (r@net54 @ 14 Nov 2014, 16:50) Donc on a un x86 totalement maitrisé optimisé comme une formule 1 par des ingenieurs qui sont les meilleurs au monde et en face on a de l'ARM qui est encore tres loin d'etre aussi optimisé et qui est moins maitrisée. Donc la marge de progression entre le x86 et l'ARM n'est pas la meme. Il suffit pas de mettre un CQFD à la fin d'une phrase pour que la phrase en question démontre quoique ce soit... En gros, là tu nous dit juste que selon toi ARM à de la marge de progression parce que selon toi ARM est actuellement moins maitrisé et moins optimisé que le x86. Mais tu démontres que dalle, tu n'as rien pour étayer, aucun argument technique. Juste du doigt levé et du pifomètre.La difference c'est l'efficacité de l'architecture:CQFD. Et au contraire, la réalité des faits montre plutôt que ça commence à stagner aussi dans la monde ARM... Regarde par exemple la progression des performances CPU entre l'A6 et l'A7 puis entre l'A7 et l'A8, la progression a très fortement ralenti... Et c'est encore pire chez la concurrence. -------------------- |
|
|
|
|
14 Nov 2014, 19:33
Message
#45
|
|
 Macbidouilleur d'Or ! Groupe : Membres Messages : 5 108 Inscrit : 1 Jul 2010 Membre no 156 073 |
Citation (r@net54 @ 13 Nov 2014, 19:02) Quant a l'histoire du cloud computing pour faire tourner ce type de soft c'est du markting et c'est sans interet. Parle pour toi ! Les solutions déportées ne sont pas l'idéal mais peuvent s'avérer fort pratiques dans un monde vraiment mobile, en tout cas, je saurais quoi en faire. Citation (r@net54 @ 13 Nov 2014, 19:02) Citation (scoch @ 13 Nov 2014, 18:27) Adobe aussi est pragmatique en travaillant à des versions déportées dans le nuage de ses applications. Photoshop Streaming fonctionne pour Chrome 0S (ARM et x86) ainsi que dans le navigateur Chrome (Windows 7 et 8). Un Mac ARM iOS X aura peut-être droit un jour à une version. Si Adobe ne passait pas a ARM cela relancerait la concurrence sur un secteur qui est soumis a un monopole délétère depuis des années, et la baisse des ventes chez Adobe va les inciter a se réveiller enfin. Donc Adobe passera a ARM c'est meme pas la question. Ce qui compte pour utiliser ces logiciels c'est plus les performances graphiques que le CPU, et la on a bien des gens qui travaillent avec uniquement les pauvres unites graphiques integrées aux Core ix... Tu es anti x86 et anti Adobe, je comprends que tu ne sois pas plus nuancé sur le sujet. Le GPU est déporté dans le nuage. Et alors ? Tu ne vois pas d'opportunités de t'en servir ? Quelle concurrence ? Je précise que je n'ai pas d'affection pour Adobe ni pour Intel, je suis agnostique comme toi  en matière d'informatique. Comment tu remplaces InDesign ? Les solutions alternatives peuvent éventuellement satisfaire un indépendant si ça lui permet de travailler avec les fichiers qu'on lui envoie (les ouvrir, les modifier et bien entendu les renvoyer dans le format de réception). Pour l'industrie graphique, il y a des standards (InDesign, QuarkXPress et bien sûr Acrobat), s'en éloigner c'est risquer de compromettre l'optimisation d'un workflow. en matière d'informatique. Comment tu remplaces InDesign ? Les solutions alternatives peuvent éventuellement satisfaire un indépendant si ça lui permet de travailler avec les fichiers qu'on lui envoie (les ouvrir, les modifier et bien entendu les renvoyer dans le format de réception). Pour l'industrie graphique, il y a des standards (InDesign, QuarkXPress et bien sûr Acrobat), s'en éloigner c'est risquer de compromettre l'optimisation d'un workflow.-------------------- L'homme n'est que poussière... c'est dire l'importance du plumeau ! Alexandre Vialatte
|
|
|
|
|
1 utilisateur(s) sur ce sujet (1 invité(s) et 0 utilisateur(s) anonyme(s))
0 membre(s) :
| Nous sommes le : 26th May 2026 - 02:02 |